
January 30, 2021 Update: If you are interested in learning the fundamentals of building Neural Network solutions then please take a look at my Patreon site. The first project will be released in approximately 2 weeks (Tier 1: source code and basic instruction – Tier 2: same as Tier 1 but with the addition of video code-walk-throughs, instruction, etc.).
First – this isn’t an article bashing Matlab – on the contrary, I’ve used and depended on Matlab as one of my many engineering tools my entire career. However, Matlab is not free and it’s not cheap as the commercial cost for Matlab is around $2,000 and $1,000 for the Deep Learning (used to be Neural Network) toolbox. So when there are alternatives for specific tasks, it’s always worth taking a closer look. The Pyrenn LM Feed-Forward (also Recurrent) Neural Network training algorithm can run in Matlab or Octave – or you can run the Python version. And it’s free. Thus if you’re developing Neural Network applications but can’t afford the cost of Matlab, then you can use the Pyrenn LM source code in Octave. Even in Matlab, you’ll achieve better overall performance using the Pyrenn LM training algorithm than if you used the Matlab LM training algorithm.
Most of my Neural Network applications efforts in the past have used Feed-Forward Neural Networks and I’ve always used the fastest training method (since graduating from back-propagation in the early days) which is the Levenberg-Marquardt optimization algorithm. In fact, only 1% of my time on any Neural Network application is spent on the training of the Neural Networks – because the LM method is so damn fast. Most of my time is spent where it needs to be – in the understanding and the design of the training and test sets. I learned long ago, that the architecture is of 2nd or 3rd order importance when compared to the quality of the training and test data sets – these are of 1st order importance.
The LM optimization algorithm has been used reliably, for decades, across many industries to rapidly solve optimization problems – as it’s known for its speed. The only potential downside is the large memory required for large problems (the Jacobian matrices become exponentially large). Fortunately, most of the Neural Network applications that I’ve worked don’t require huge data sets. And typically, if you have a large data set – such as with image processing, the intermediate step is to perform some type of Principal Component Analysis (PCA) such that the primary features of the large data set can be extracted and represented with a smaller data set, which is then more tractable with a Neural Network.
This article discusses the results of testing both the Pyrenn LM and Matlab LM training algorithms on a simple quadratic curve. The summary results are shown below. The section following that is a technical appendix which discusses the details of all of the testing. At the very end of this article are three videos: 1) using the code in Matlab, 2) using the code in Octave, and 3) an informal code “walk-through”. Following the videos is a link to a downloadable zip file which contains all of my source code (and the Pyreen source code) used for the analysis in this article so that you can run it yourself – either in Matlab or in Octave.
Before going any further, you can obtain the Pyrenn library with both Python and Matlab code libraries here – https://pyrenn.readthedocs.io/en/latest/. A big “Shout Out” to Dennis Atabay and his fellow Germans for not only building this awesome algorithm – but doing it in two languages, Matlab and Python. Then again, most Germans are bilingual (at a minimum) so I suppose it’s to be expected. The code is very well commented – but you’ll need to use the Google language translator – German to English.
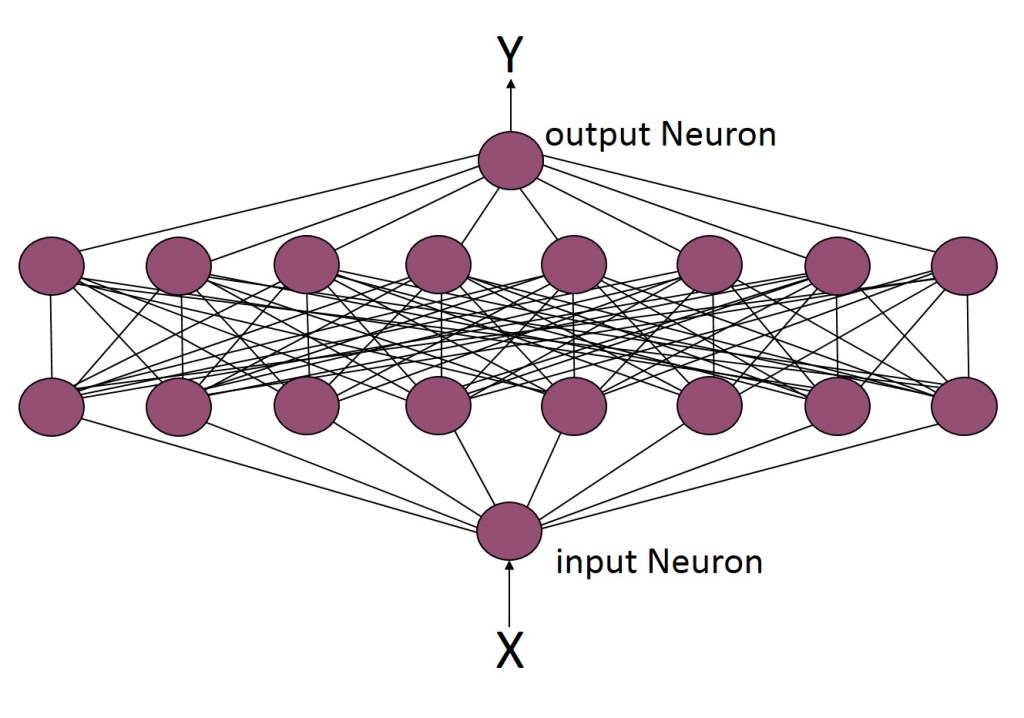
System Modeled for Bench Testing the Matlab and Pyrenn Neural Networks
A simple test case that can be used to bench test any Feed-Forward Neural Network is the standard quadratic equation as shown below. It’s not complex but it is nonlinear and it shouldn’t be hard to train a Neural Network to “learn” the nonlinear curve properties and reasonably be able to extrapolate, to some degree, outside the training regime.
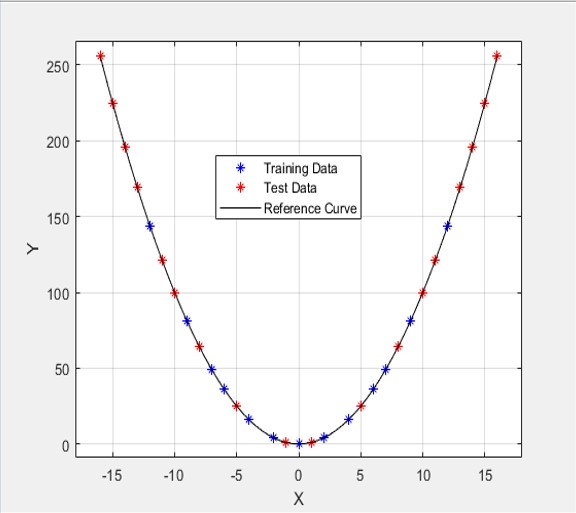
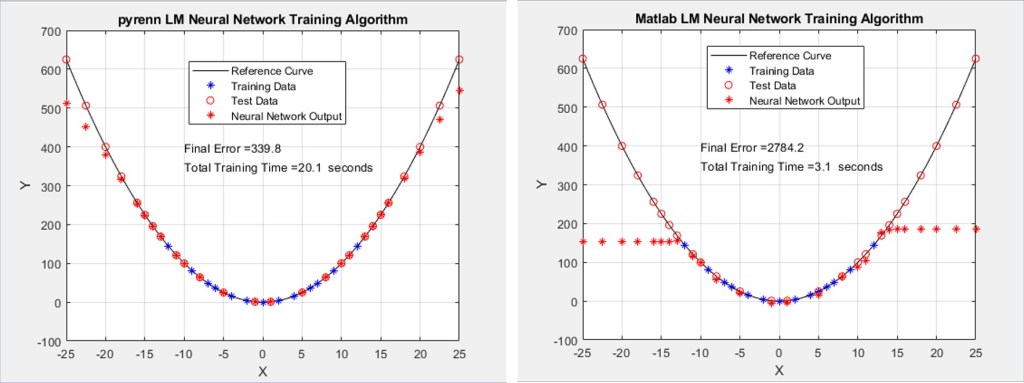
The actual quadratic curve used for this article is shown below. The blue stars represent the Neural Network training points – the corresponding X and Y coordinates for each point are the input and output training data sets respectively. The red stars represent the test points – note that the test set lies both inside the training area as well as outside of it. This is actually used as Test Case #1 – the farthest “outside” test point reaches approximately 33% beyond the training regime.
Testing Methodology and Procedure
Three tests cases were set up for bench testing both the Matlab LM and Pyrenn LM trained Neural Networks. These test cases reached outside the training regime by 33% (Test Case #1), 108% (Test Case #2), and 316% (Test Case #3). The point was to push the Neural Networks hard on the testing (how well do they perform outside the training regime?).
In each of the test scenarios, the Matlab LM algorithm was used to train 10 Neural Networks – the best one, with the lowest test error, was selected to compete against the Pyrenn LM algorithm. In a similar manner, the Pyrenn LM algorithm was used to train 10 Neural Networks, and again, the best one was selected as the competitor.
For Test Case #1 and Test Case #2, this process was also performed for three different architectures: 1) one middle layer with 4 Neurons, 2) two middle layers with 4 Neurons each, and 3) two middle layers with 8 Neurons each. For Test Case #3, only the first and last architectures were used for testing – the reason being that I was running out of time for getting this article finished and posted (my own self-imposed deadline).
Performance Summary
In the plots below, the three types of architectures tested are represented along the X-axis by: (1) middle layer with 4 Neurons, (2) two middle layers with 4 Neurons each, and (3) two middle layers with 8 Neurons each. The Y-axis is the average error for all 10 Neural Networks that were tested for each of these architectures.
Test Case #1 represents a data set that reaches approximately 33% beyond the training regime boundary. Test Case #2 represents a data set that reaches approximately 108% beyond the training regime boundary. And Test Case #3 is “really out there” with a reach of 316% beyond the training regime boundary. Of course – the further away from the training regime, lower performance is expected.
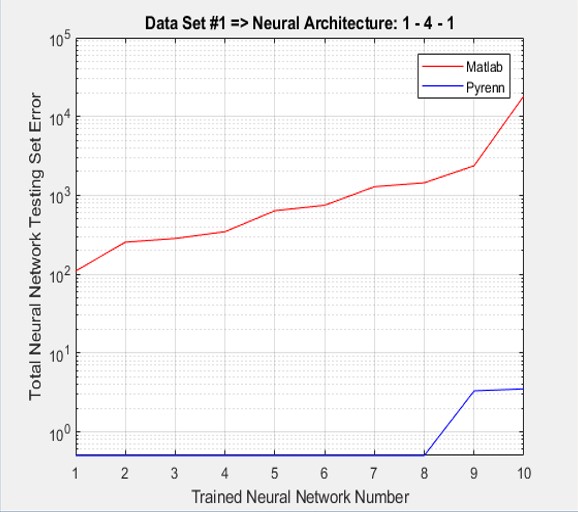
In all cases, the Pyrenn LM algorithm (blue line) far outperformed the Matlab LM algorithm (red line) – the lower the error, the better the performance.
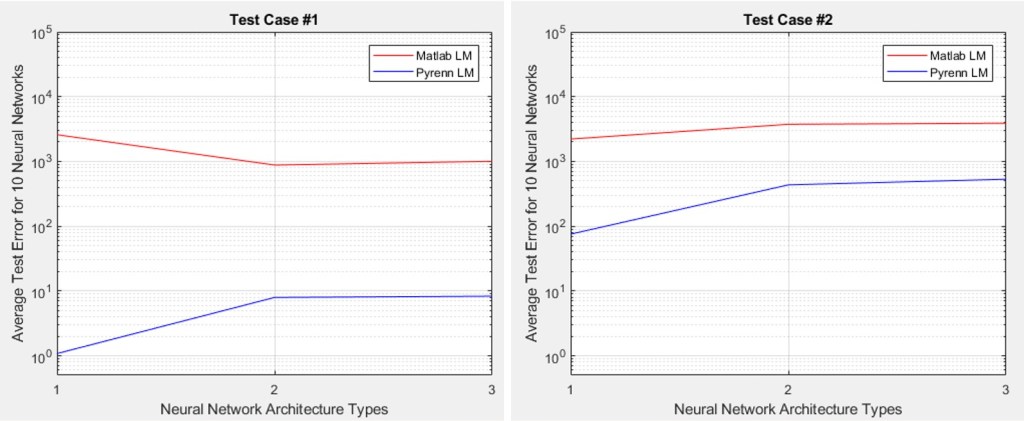
Note that increasing the architecture size of the Neural Network does not lead to increased performance – that is, adding more middle layers and more Neurons in each layer. Smaller is better for this application.
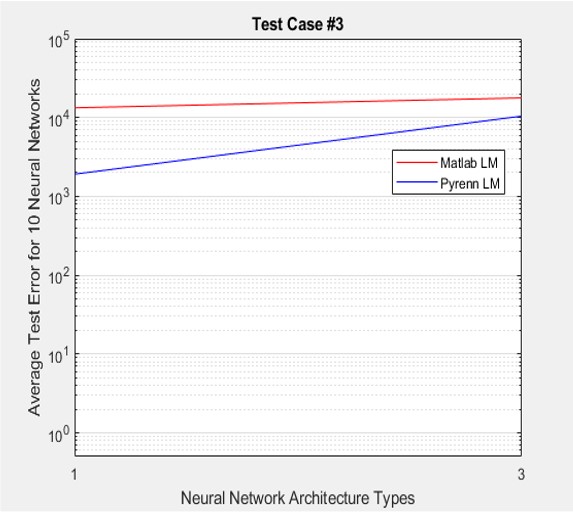
The results generated by the Pyrenn LM Neural Network training algorithm are impressive and, based on my experience in the past, are likely indicative of the level of performance to be expected with more complex systems.
More test details can be obtained by reviewing the Technical Appendix below.
Technical Appendix
The testing process was driven by: 1) increasing the number of outside test points – referred to as Test Case #1, Test Case #2, and Test Case #3), and 2) varying the Neural Network architecture for each of the test cases.
Test Results for Data Set #1
1 Middle Layer – 4 Neurons
In this first test case, a simple Neural Network architecture is used – one “middle” layer with four Neurons – as shown below.
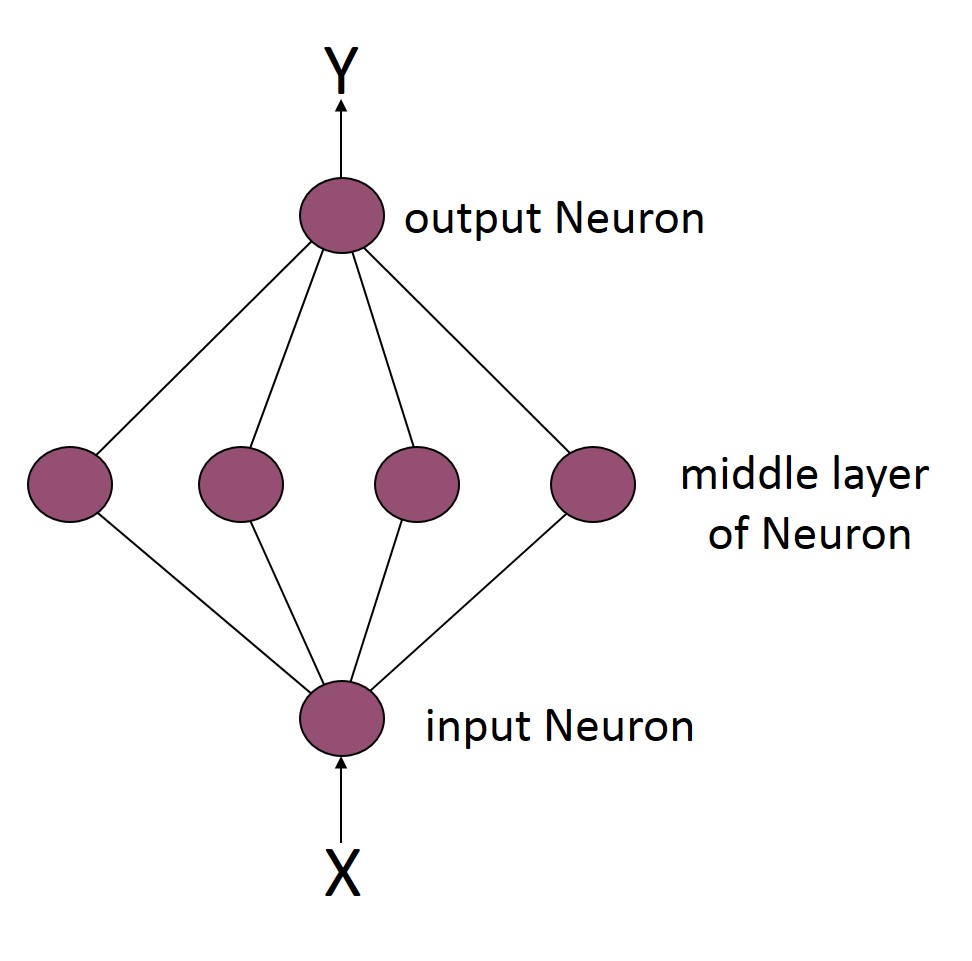
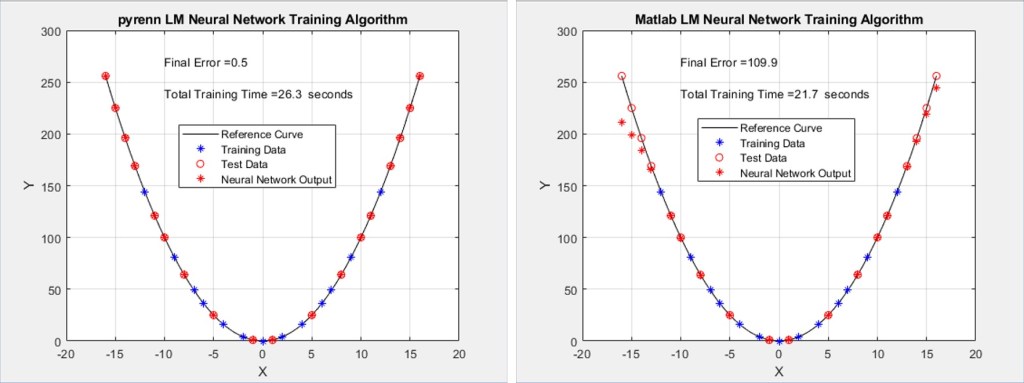
The results of training Neural Networks with both the Pyrenn and Matlab LM training algorithms are shown below. The red circles on the curve are the target test points – the hope is that the Neural Network will correctly output those points (the output Y coordinate given the input test X coordinate) which are represented by red stars. Even if they are not exact, depending on the overall trend, it can still be considered good performance.
The blue stars are the Neural Network output (Y coordinate for the given X coordinate input) for the training points. The expectation there is that if the training is good, at a minimum the Neural Network will be able to correctly output the Y coordinate training point. If it can’t do that correctly then there’s no point in looking at the test points performance.
Each of the two plots represent the best performing Neural Network, out of a total of 10 – that is, the best one out of 10 generated by the Pyrenn LM algorithm, and the best one out of 10 generated by the Matlab LM algorithm.
As shown below, the accumulated test errors were far less for the Pyrenn LM-trained Neural Networks than those trained by the Matlab LM algorithm. Note that the errors were sorted from lowest to highest.
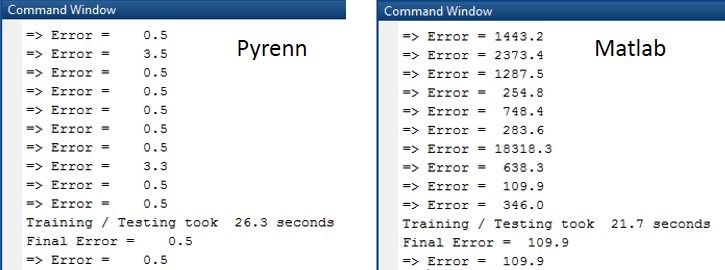
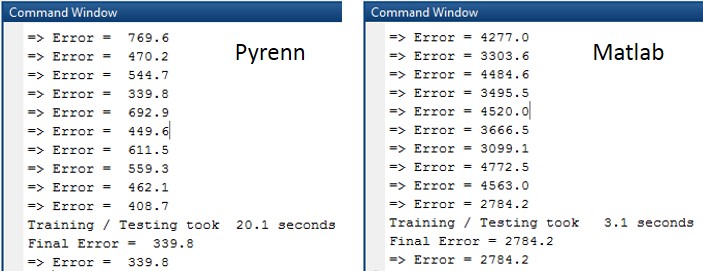
The Command Window output from each session is shown below. Note that the difference in errors between the two LM algorithms is between two and four orders of magnitude.
2 Hidden Layers – 4 Neurons Each
In this case, another “middle” layer was added with four more Neurons.
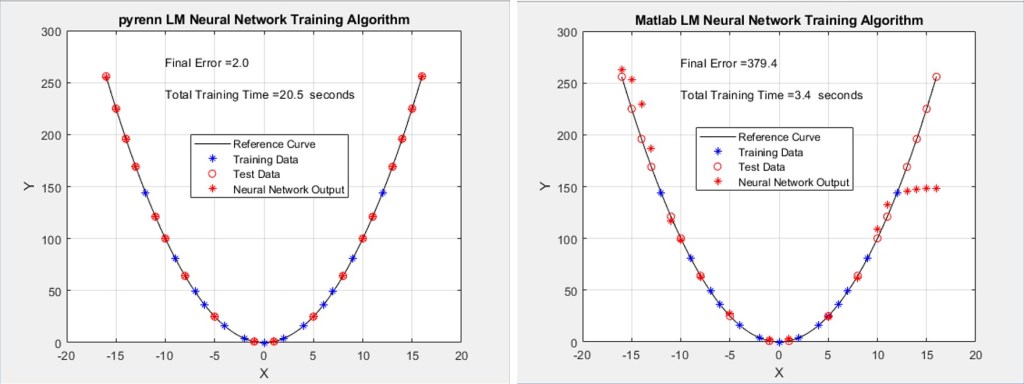
While the performance of the Pyrenn LM-trained Neural Networks was maintained – the change in architecture resulted in worse performance for the Matlab LM-trained Neural Networks. Each of the two plots represent the best performing Neural Network, out of a total of 10 – that is, the best one out of 10 generated by the Pyrenn LM algorithm, and the best one out of 10 generated by the Matlab LM algorithm.
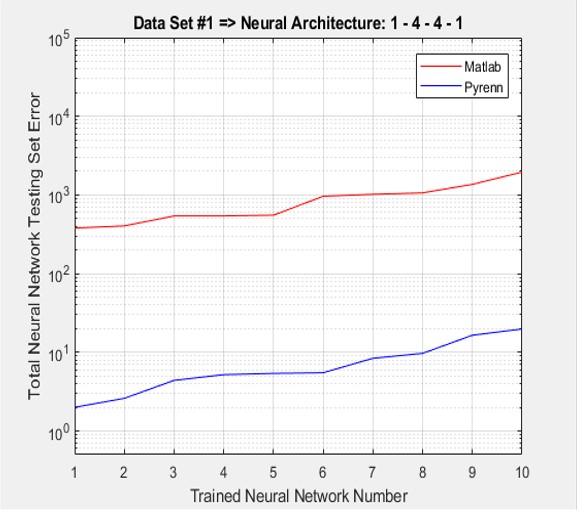
Once again the accumulated errors for the Pyrenn LM-trained Neural Networks were far less than those of the Matlab LM-trained Neural Networks. Note that the errors were sorted from lowest to highest.
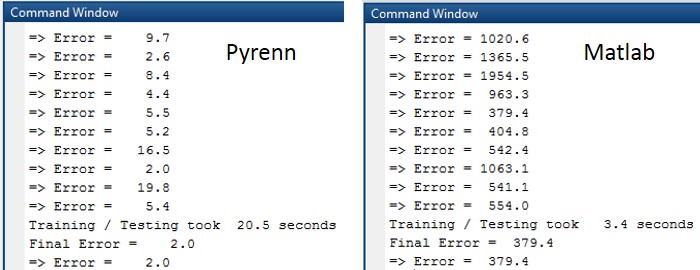
The Command Window output for each session is shown below. Note that the difference in errors between the two LM algorithms is between two and three orders of magnitude.
2 Hidden Layers – 8 Neurons Each
Again the architecture was modified to have eight Neurons in each of two “middle” layers, as shown below.
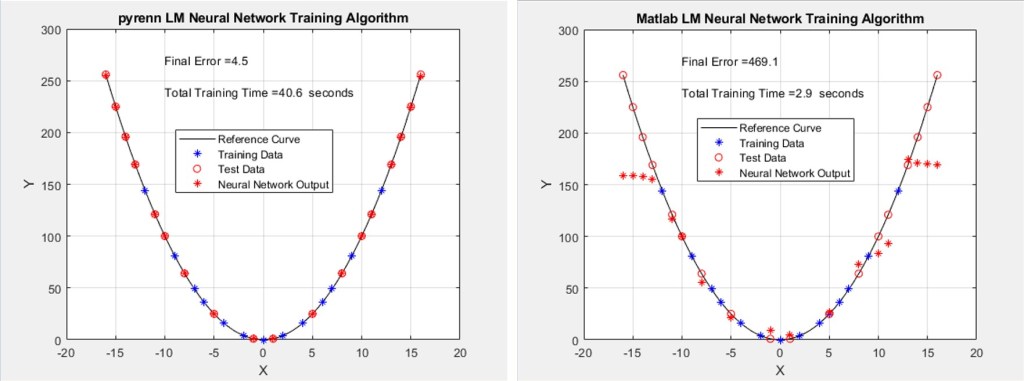
The performance of the Matlab LM-trained Neural Networks continued to deteriorate while the Pyrenn LM-trained Neural Networks maintained good performance. Each of the two plots represent the best performing Neural Network, out of a total of 10 – that is, the best one out of 10 generated by the Pyrenn LM algorithm, and the best one out of 10 generated by the Matlab LM algorithm.
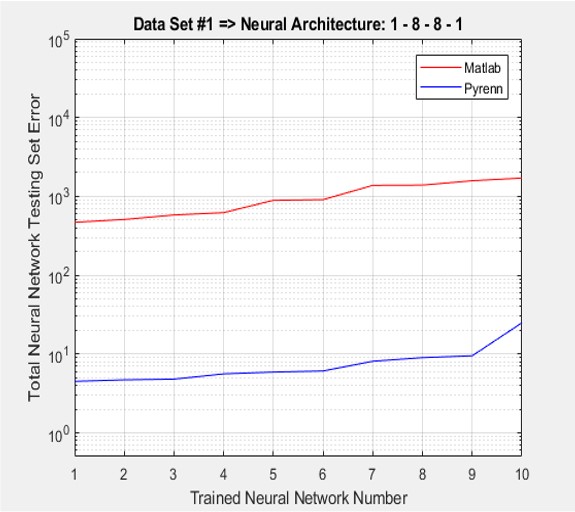
As before, there was a significant difference between the performances of the Neural Networks trained by the Pyrenn LM algorithm and those trained by the Matlab LM algorithm. Note that the errors were sorted from lowest to highest.
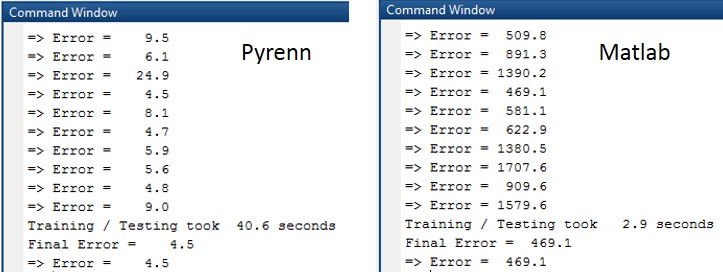
The Command Window output for each of the training / test sessions is shown below. Note that the difference in errors between the two LM algorithms is between two and three orders of magnitude.
Test Results for Data Set #2
For this second test case, the number of test data points, outside the training regime, was increased. Whereas for the first test case, the minimum and maximum test points were (-16, 256) and (+16, 256), the new test range minimum and maximum test points were (-25, 625) and (+25, 625).
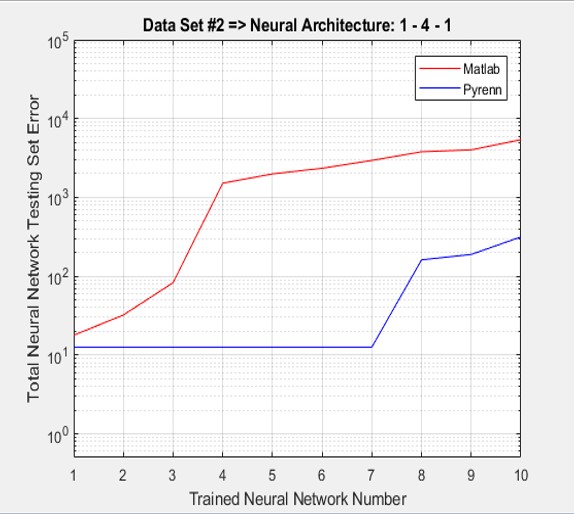
1 Hidden Layer – 4 Neurons
In this first test case, a simple Neural Network architecture is used – one “middle” layer with four Neurons. The results of training Neural Networks with both the Pyrenn and Matlab LM training algorithms are shown below. Each of the two plots represent the best performing Neural Network, out of a total of 10 – that is, the best one out of 10 generated by the Pyrenn LM algorithm, and the best one out of 10 generated by the Matlab LM algorithm.

While the performance of a particular Matlab LM-trained Neural Network was good, the accumulated test errors were far less for the Pyrenn LM-trained Neural Networks than those trained by the Matlab LM algorithm (because the majority of the Matlab LM-trained Neural Networks did poorly). Note that the errors were sorted from lowest to highest. One way to interpret the plot is that the Pyrenn LM algorithm generated a lot more high-performing Neural Networks than the Matlab LM algorithm.
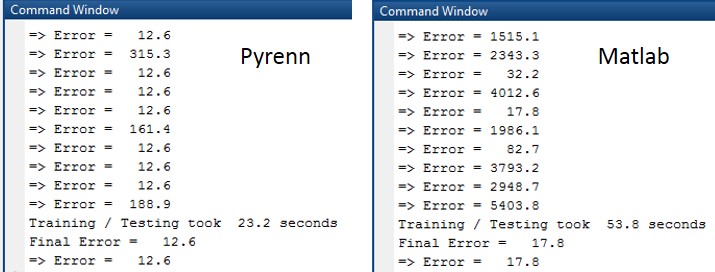
The Command Window output for each of the training / test sessions is shown below. Note the large percentage of Pyrenn LM generated Neural Networks with low test errors.
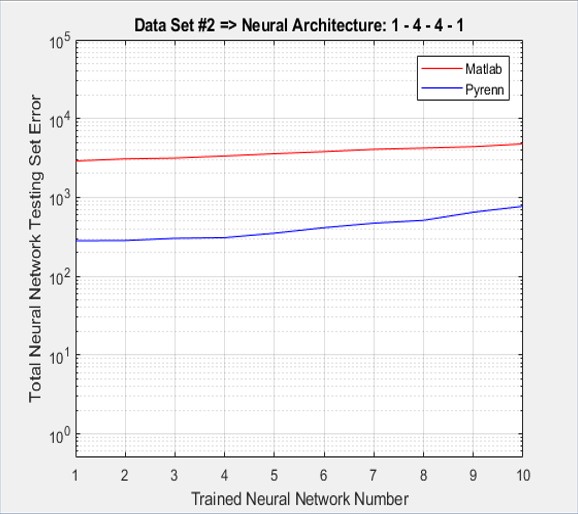
2 Hidden Layers – 4 Neurons Each
In this case, another “middle” layer was added with four more Neurons. The performance of the Matlab LM-trained Neural Networks deteriorated tremendously while the Pyrenn LM-trained Neural Networks maintained good performance. Each of the two plots represent the best performing Neural Network, out of a total of 10 – that is, the best one out of 10 generated by the Pyrenn LM algorithm, and the best one out of 10 generated by the Matlab LM algorithm.

As shown below, the accumulated test errors were far less for the Pyrenn LM-trained Neural Networks than those trained by the Matlab LM algorithm. Note that the errors were sorted from lowest to highest.
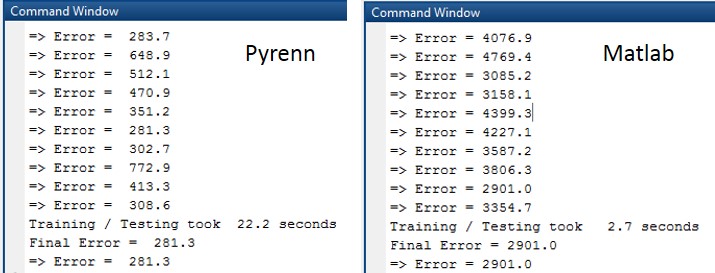
The Command Window output for each of the training / test sessions is shown below. Note that the difference in the test errors are an order of magnitude.
2 Hidden Layers – 8 Neurons Each
In this case, the architecture was modified to have eight Neurons in each of two “middle” layers. The Pyrenn LM Neural Network performance degraded a little while the Matlab LM Neural Network performance was just slightly worse than the already “very bad” performance with the previous architecture. Each of the two plots represent the best performing Neural Network, out of a total of 10 – that is, the best one out of 10 generated by the Pyrenn LM algorithm, and the best one out of 10 generated by the Matlab LM algorithm.
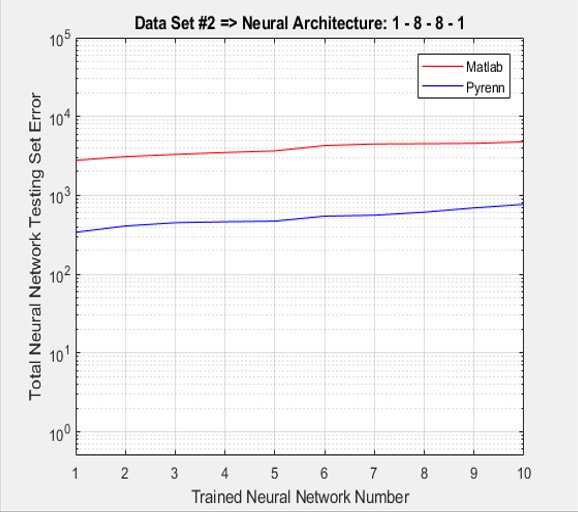
As shown below, the accumulated test errors were far less for the Pyrenn LM-trained Neural Networks than those trained by the Matlab LM algorithm. Note that the errors were sorted from lowest to highest error.
The Command Window output for each of the training / test sessions is shown below. Note that the difference in the test errors is an order of magnitude.
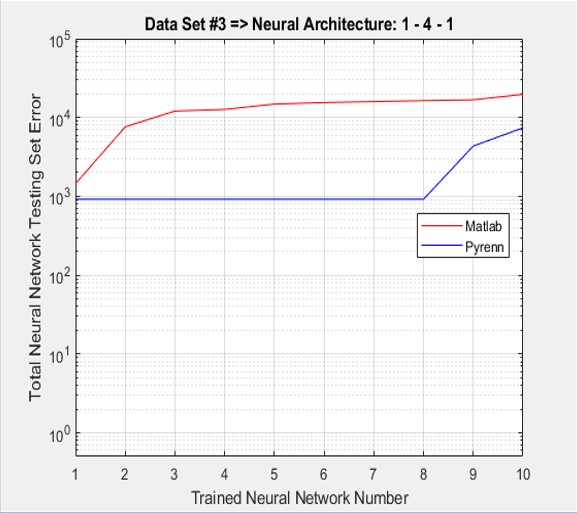
Test Results for Data Set #3
For this third test case, the number of test data points, outside the training regime, was increased again. Whereas for the second test case, the minimum and maximum test points were (-25, 625) and (+25, 625) , the new test range minimum and maximum test points were (-50, 2,500) and (+50, 2,500).
1 Hidden Layer – 4 Neurons
In this first test case, a simple Neural Network architecture is used – one “middle” layer with four Neurons. The results of training Neural Networks with both the Pyrenn and Matlab LM training algorithms are shown below. Each of the two plots represent the best performing Neural Network, out of a total of 10 – that is, the best one out of 10 generated by the Pyrenn LM algorithm, and the best one out of 10 generated by the Matlab LM algorithm.

As shown below, the accumulated test errors were far less for the Pyrenn LM-trained Neural Networks than those trained by the Matlab LM algorithm. Note that the errors were sorted from lowest to highest.
The Command Window output for each of the training / test sessions is shown below. Note that the difference in the test errors is approximately an order of magnitude.
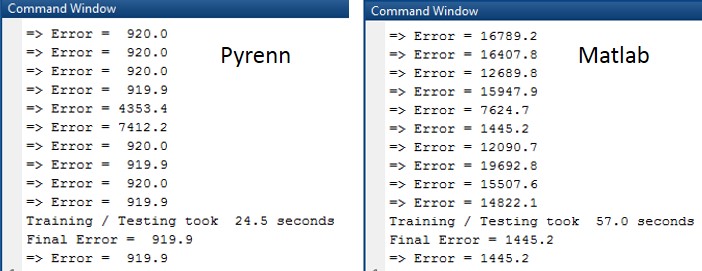
2 Hidden Layers – 8 Neurons Each
In this case, the architecture was modified to have eight Neurons in each of two “middle” layers. The Pyrenn LM Neural Network performance degraded significantly but the Matlab LM Neural Network performance totally fell apart. Each of the two plots represent the best performing Neural Network, out of a total of 10 – that is, the best one out of 10 generated by the Pyrenn LM algorithm, and the best one out of 10 generated by the Matlab LM algorithm.
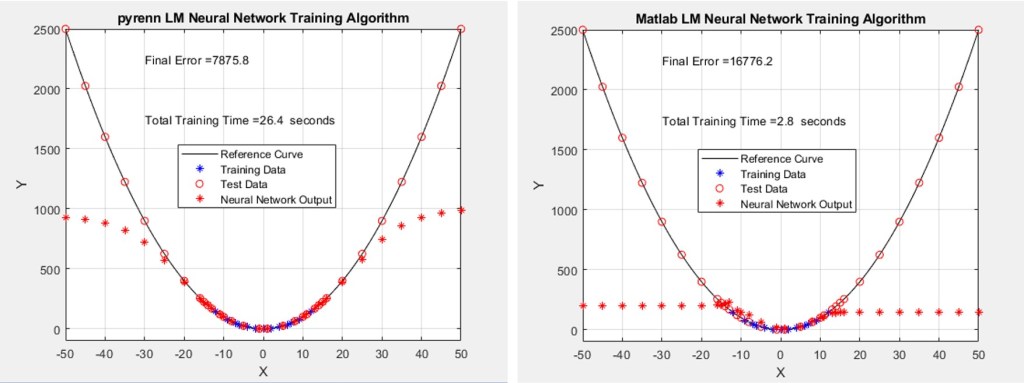
As shown below, the accumulated test errors were less for the Pyrenn LM-trained Neural Networks than those trained by the Matlab LM algorithm. Note that the errors were sorted from lowest to highest.
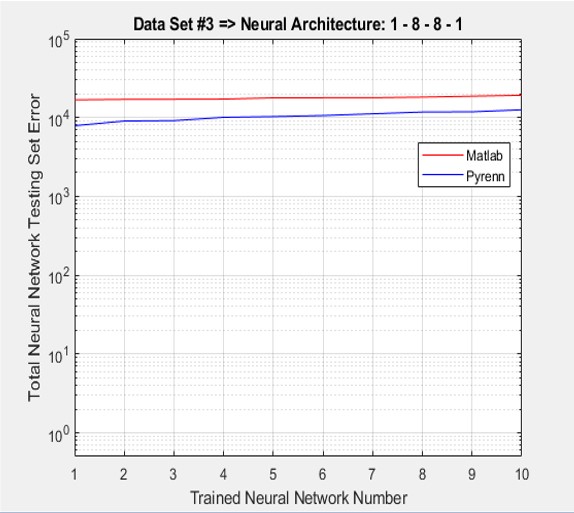
The Command Window output for each of the training / test sessions is shown below.

Software Discussion
The following three videos cover the following: 1) running the code in Matlab, 2) running the code in Octave, and 3) a “code walk-through”.
Video #1 – Running the Code in Matlab
The video below shows how to run the software in Matlab. Click on the lower right square icon (next to the sound / speaker icon) to enlarge the video to almost the size of the monitor in order to more easily view it.
Video #2 – Running the Code in Octave
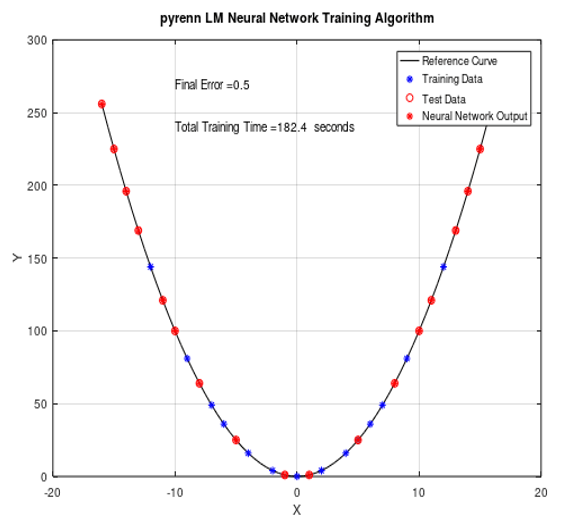
Note that it takes longer to run the Pyrenn LM algorithm in Octave – but the results are similar to those obtained in Matlab. In the example shown below, the run time was approximately 182 seconds (3 minutes, 2 seconds) vs a similar run in Matlab that would take 26 seconds.
However, if you’re using Octave because you don’t have access to Matlab, then the additional training time is a small price to pay.
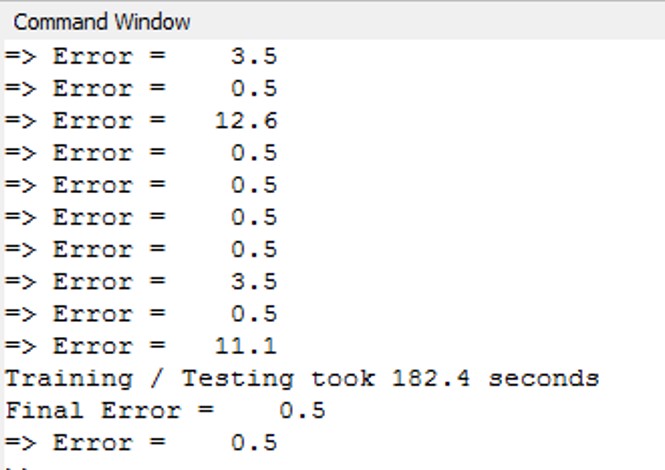
The plot below, which corresponds to the above test run, shows the results of running the Pyrenn LM training algorithm and using Test Case #1 with the simple, single middle layer with 4 Neuron architecture.
The video below shows how to run the software in Octave. Click on the lower right square icon (next to the sound / speaker icon) to enlarge the video to almost the size of the monitor in order to more easily view it.
Video #3 – Code Walk-Through
The video below is an informal “code walk-through” of the Matlab functions. Click on the lower right square icon (next to the sound / speaker icon) to enlarge the video to almost the size of the monitor in order to more easily view it.
Software Download
The software (Matlab and Pyrenn source code and directories), as a zip file, can be downloaded from the link below.

Leave a comment